It is now a commonplace that the availability of computer corpora permits, as our subtitle suggests, “a more quicker, easier and more effective” way of gathering data for both synchronic and diachronic research. Taken from the British National Corpus, which provides the main source of our data, our subtitle also illustrates well the competing forms of adjective comparison in contemporary spoken English that we will discuss here. The primary competition is between the so-called inflectional comparative (e.g. easier) which is the older form, and the newer periphrastic construction (e.g. more effective), with the double comparative (e.g. more quicker), now considered non-standard, much less frequent.1
The use of a large computerized data base such as the British National Corpus allows us to demonstrate that some adjectives overwhelmingly show a preference for the newer periphrastic mode of comparison, some for the older inflectional form, while some fluctuate between the two. We will also compare our results with a diachronic study done by Kytö (1996a). This yields a broad overview of the main lines of historical development which have shaped the modern system, at the same time as it allows us to pinpoint certain key stages in the transition from the earlier to the present-day system.
The Late ME and EModE data used in the diachronic study are of necessity written, while ours from modern English are by choice spoken. Our original interest in the use of the non-standard double comparatives motivated our initial decision to begin our study of contemporary English with part of the spoken rather than written data in the British National Corpus because these double forms are now almost, if not entirely, confined to colloquial spoken English (see further in 3). This does, however, pose a problem for diachronic comparison, which we try to remedy somewhat by considering the material in the ARCHER corpus (A Representative Corpus of Historical English Registers; see Biber et al. 1994a and 1994b). For the purposes of this study we have taken from ARCHER some 1.4 million words representing six text types2 sampled from the period between 1650–1990. Thus, the first subperiod from ARCHER overlaps with the final subperiod of the Early Modern English section of the Helsinki Corpus, and the last subperiod from ARCHER brings us up to the modern period covered by the British National Corpus. This allows us to bridge the time gap between the Early Modern and contemporary English data. Finally, we outline some issues requiring further research and suggest some ways of investigating them.
The topic of adjective comparison has been discussed in general terms in most of the grammars of contemporary English (see e.g. Quirk et al. 1985), in the standard handbooks on the history of English (see e.g. Jespersen 1949), as well as in a few specialist works (see e.g. Pound 1901, Knüpfer 1922 and Rohr 1929). Historically speaking, the so-called periphrastic constructions with more and most (e.g. more vigorous, most vigorous) are innovations. In Old English the comparative and superlative forms of adjectives were uniformly marked by inflectional endings; compare modern English greater and greatest. The periphrastic forms first appeared in the thirteenth century (see Mitchell 1985: 84–5 for the few attested possible examples in Old English), possibly under the influence of Latin (and to a lesser extent French). They gained ground steadily after the 14th century until the beginning of the 16th century when they had become as frequent as they are today (see Pound 1901: 19).
As is often the case with syntactic innovations in the history of English, a variety of factors has been cited as responsible. We have already noted above historians’ attribution of the development to foreign influence. At the same time others pointed to stylistic factors such as speakers’ needs for emphasis and clarity. More generally speaking, however, the loss of inflectional morphology accompanying the gradual shift in English toward a more analytical syntax provided a typology consistent with the periphrastic construction. Nevertheless, what we will show is that after the newer forms are introduced, change proceeds along a divergent track. After an initial spurt in the use of the new periphrastic type of comparison in some environments, the newer forms eventually oust the older ones completely. In other environments, however, the newer forms recede in favor of the older inflectional type. The majority of both comparative and superlative adjectives in present-day English are in fact of the inflectional type, contrary to what one might expect from the general trend in English towards a more analytical syntax.
The availability of the new periphrastic constructions also added yet one more option to the system, a hybrid form in which more and most are combined with the inflectional adjective, e.g. more quicker and most hardest. These are usually called multiple or double comparatives.3 Inflectional double forms are also found in a limited number of words such as lesser, worser, bestest, more better. As a consequence, during the Middle English and Early Modern English periods, there were three alternative forms of comparison for an adjective such as easy: inflectional (easier/easiest), periphrastic (more easy/most easy) and double (more easier/most easiest).
As we said above, the main source of data for our analysis is the British National Corpus of 100 million words of contemporary spoken and written English.4 Due to limitations of space and time we have confined ourselves here to an exploratory sub-corpus of 2,176,000 words of spoken dialogue from the southern region of England which we indexed for search purposes using WordCruncher. While we hope to extend the analysis in further work to look at regional and other social parameters such as class, age and sex, in this paper we have concentrated primarily on linguistic factors constraining the variation. In the following analysis we have also relied heavily on the basic categories set up by Kytö (1996a) in her study of rivalling forms of adjective comparison in the Helsinki Corpus of English Texts so that we can maintain some diachronic continuity. This study included some 950,000 words from the Late Middle (1350–1500) and Early Modern English (1500–1710) sections of the corpus.
Table 1 provides an overview of the data grouped in terms of the comparative and superlative forms of defective and non-defective adjectives.5 We have divided adjectives into these two broad groups, according to whether the forms of comparison are based on the same root as the positive form or not. Instances of “umlaut” comparison (e.g. elder/older, eldest/ oldest) are included in the group of non-defective adjectives.6 The group of defective or heterogeneous words includes the instances for which the comparative and superlative are not from the same root as the positive (e.g. good/better/best).
Table 1. Non-defective v. defective forms of adjective comparison in the British National Corpus (spoken component, South, dialogue), compared with the Helsinki Corpus of English Texts (Late Middle and Early Modern English).
| NON-DEFECTIVE |
DEFECTIVE |
|||||
| Comparative | Superlative | Total | Comparative | Superlative |
Total |
|
| BNC | 1726 (74%) | 592 (26%) | 2318 | 741 (60%) | 489 (40%) | 1230 |
| EModE | 656 (47%) | 750 (53%) | 1406 | 489 (41%) | 709 (59%) | 1198 |
| LME | 388 (52%) | 356 (48%) | 744 | 258 (42%) | 359 (58%) | 617 |
Out of the total of 3,548 adjectives in our sample from the British National Corpus 65% (N = 2,318) are non-defective and 35% (N = 1,230) defective. The comparative forms are more frequent than the superlative ones in each group of adjectives, but particularly for the non-defective adjectives, where they account for nearly 3/4 of the occurrences. This supports the observation made by Quirk et al. (1985: 463) that in present-day English the comparative is on average more frequent than the superlative.
The analysis of 3,965 adjectives from the Late Middle and Early Modern periods revealed less asymmetry in the distribution of words between the categories of defective (46%) and non-defective (54%), though the non-defective group still accounts for more than half the data (Kytö 1996a). In the group of non-defective forms, the comparative and superlative forms are represented to more or less the same extent in the two main periods; in the group of defective forms, the superlative forms cover some 60% of the data.
Table 2 shows the distribution of defective adjectives. The forms better/ best account for about 80% of the examples, followed by worse/worst, later/latest/last and a few others, i.e. further/furthest and upper. In the Late ME and EModE data last was by far the most common item, due to the high frequency of set phrases and formulaic expressions such as on Sunday last, etc. Three instances of double forms were found in this group of adjectives, two of them with more better (one in a mystery play from ?a1475 and the other in a private letter from a1510) and one with most best (in a preface by Caxton from 1477–1484).7
Table 2. Defective adjectives (BNC, spoken, South, dialogue).
| Comparative |
Superlative |
||
| BETTER | 586 | BEST |
401 |
|
WORSE |
139 | WORST | 57 |
| LATER | 7 |
LATEST, LAST |
28 |
|
OTHER |
9 | OTHER | 3 |
‘OTHER’ = FURTHER 7, UPPER 2 ‘OTHER’ = FURTHEST 3
In our data from the British National Corpus we found the following two examples of double comparatives with defective adjectives (1–2) and three double superlatives (3–5); for comparison, it is of interest to point out that the only instances of this type found in the written component of the British National Corpus (90 million words) were three instances of the form bestest (in rather jocular uses as in my bestest friend):8
(1) – ... get an electrical one, they’re much more <trunc> chea </trunc>, they’re much more better, er shh, shh you’re done <vocal desc=laugh> you don’t have to spend all day mowing...9
[“one” = an electrical lawn mower]
(2) – They’ve come worse off.
– Worser?
– That’s not a word.
– Worse off.
(3) – I already bought in Woolworths once! Woolworths, they have them <trunc> an </trunc> they have
– They got them in Woolworths.
– the best
– Mm.
– they are the most best people that
– They’re good!
– Yeah.
(4) – Where can we play.
– This is the bestest one you can read. Read it for Father Christmas.
(5) – But <unclear> my nails. Look even my bestest one.
In the first example the speaker is Marsha (13 yrs), who obviously first aims at the double form more cheaper but ends up using the defective form more better. In the second example Grace, a 15-year-old female student speaking with London accent, notices she has produced the non-standard form worser. This speaker has a social background representative of top or middle management, or of administrative or professional ranks. Her interlocutor is an unidentified person, and the conversation takes place in a school in the ‘Greater London’ area. In the third example the informant is Christopher, a seven year old schoolchild of unknown social background.
But not only very young speakers produce double forms. The two instances of bestest in examples (4–5) are produced by adult speakers under or around 30. Example (4), is by Chris, a 26-year-old warehouse operator with speech habits characteristic of central south-west England. He is still active in education and his social status based on occupation is given as semi-skilled or unskilled. Example (5) comes from Gail, a 30-year-old housewife, who left school aged 15 or 16 and is from the same dialect area and representative of the same social class as Chris. With this limited sample of double forms it would be premature to hazard too many guesses about their possible social distribution. We leave this for further study when we have had time to examine more spoken data. Because the group of non-defective adjectives is of more interest for observing the competition among the three forms, we will not say any more about the defective adjectives.
Table 3 shows the distribution of inflectional and periphrastic forms in our corpus. Out of a total of 2,318 non-defective adjectives most comparatives are of the inflectional type (84%) as are superlatives (73%). Compared with the results obtained in the study of Late Middle and Early Modern English, we can see a gradual increase in the inflectional forms for both comparatives (from 55% to 59%) and superlatives (from 45% to 50%), with a corresponding decline in periphrastic forms in comparatives (from 45% to 41%) and superlatives (from 55% to 50%).
The distribution of comparative forms remained remarkably steady across the Late Middle and Early Modern English periods. Except for a change of 5% in the use of the periphrastic superlative as compared to inflectional comparative (4%), no major differences can be seen along the diachronic axis. From the 1420s on, the inflectional form prevails in approximately 60% of the instances recorded. Nevertheless, seen from the vantage point of contemporary English, the study appears to have intersected the change in the superlative forms at a point where the periphrastic forms first outnumber the inflectional ones, followed by a resurgence of the inflectional type.
Table 3. Inflectional and periphrastic forms in the British National Corpus (spoken component, South, dialogue), compared with the Helsinki Corpus (Late Middle and Early Modern English).
| COMPARATIVE |
SUPERLATIVE |
|||||
| Inflectional | Periphrastic | Total | Inflectional | Periphrastic | Total | |
| BNC | 1456 (84%) | 270 (16%) | 1726 | 433 (73%) | 159 (27%) | 592 |
| EModE | 382
(59%) |
267 (41%) | 649 | 370 (50%) | 366 (50%) | 736 |
| LME | 211 (55%) | 172 (45%) | 383 | 152 (45%) | 189 (55%) | 341 |
This is shown in the graph in Figure 1, where the frequencies of occurrence of the inflectional and periphrastic types of comparison begin to proceed along divergent tracks after the end of the Early Modern English period. In the Early Modern period both types compete fairly evenly, but by the Modern English period the inflectional forms have reasserted themselves to the point where they outnumber the periphrastic forms by roughly 4 to 1. In the category of superlatives the drop in the use of the periphrastic form takes place in the second subperiod (1570–1640). Thus, the crucial period during which the inflectional forms increase and the periphrastic forms decrease to achieve their present day distribution occurs during the late modern English period, i.e. post 1710.
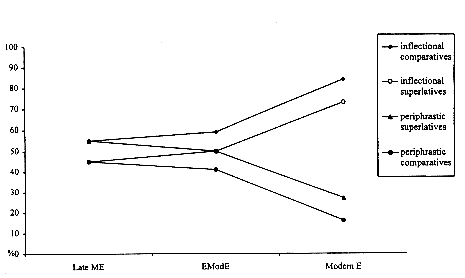
Figure 1. Percent of periphrastic and inflectional forms of adjective comparison in Late Middle, Early Modern and Modern English.
To some extent, the largeness of the gap between the Early Modern to Modern English periods is an artefact of our sample, reflecting the difference between spoken and written language. If we look at the ARCHER corpus to fill in the intervening years between the written material in the Helsinki Corpus and our modern spoken material from the British National Corpus, we find overall the same trends from 1750 to 1950. The progression towards the increasing use of the inflectional forms (from 52% to 69%) and the corresponding decline in the periphrastic forms (from 48% to 31%) is especially clear for the comparatives, as can be seen in Table 4. By contrast, there is very little fluctuation in the superlative forms. The inflectional forms are only slightly more frequent than the periphrastic ones during all subperiods.
However, when we look at the ARCHER data for the 20th century (i.e. 1900–1990), we find that 64% of comparatives are inflectional and 36% periphrastic. For the superlatives, 59% are inflectional and 41% periphrastic. The lower frequencies of inflectional forms in ARCHER compared to the British National Corpus can be accounted for by the fact that ARCHER draws on written material compiled of different text types like the Helsinki Corpus.
Table 4. Inflectional and periphrastic forms in the ARCHER corpus in subperiods by half-centuries from 1750–1950.
| COMPARATIVE |
SUPERLATIVE |
|||||
| Inflectional | Periphrastic | Total | Inflectional | Periphrastic | Total | |
| 1750–1800 | 216 (52%) | 203 (48%) | 419 | 272 (53%) | 246 (47%) | 518 |
| 1800-1850 | 143 (64%) | 79 (36%) | 222 | 120 (52%) | 111 (48%) | 231 |
| 1850-1900 | 326 (67%) | 158 (33%) | 484 | 221 (55%) | 179 (45%) | 400 |
| 1900-1950 | 188 (69%) | 86 (31%) | 274 | 72 (53%) | 65 (47%) | 137 |
In both our data and the Helsinki Corpus data the main rivalry is between the inflectional and periphrastic forms. The double forms are marginal both then and now. In the Helsinki Corpus the double comparative forms account for only 1% of the examples in both periods, while the double superlatives decline slightly from roughly 4% in the Late Middle English period to 2% in the Early Modern.
In our sample of the British National Corpus we found 8 examples of double comparative forms (6–13 below) and 2 of double superlatives (14–15).
(6) – go out now cos there’s more older ones doing it.
(7) – This way, it’s more easier to see, not quite so many leaves.
(8) – It’s much more warmer in there.
(9) – Yeah but if you think about it, people laugh when you say oh like I believe in fate, bit more easier to believe than believing in somebody up there like looking at us innit?
(10) – Perhaps, in a slightly more clearer way than you did.
(11) – She can cut that quite short on top so it’s more fuller.
(12) – and we went in and like the vicar greets you at the door don’t he and she was like <unclear> up to the vicar like, you know, she’s more fucking heavier than thou
(13) – What could be more quicker and easier and more effective than that?
(14) – He said, he said I’m the most beautifulest girl in the world!
(15) – Are, are Manchester United not the most cockiest fans going aren’t they?
The low incidence of double forms overall is due at least partly to the continuing influence of standardization, particularly 18th century and modern grammarians’ condemning of the construction as non-standard. Thus, no instances of double forms were found for the post-1640s subperiod of the Early Modern English period, which also reflects the fact that the Helsinki Corpus contains only written material. Although double forms were once in use in the literary language, e.g. “we will grace his heels with the most boldest and best hearts of Rome [Shakespeare, Julius Caesar III, I, 120]”, they gradually but nevertheless virtually disappeared from standard written English.
An examination of the ARCHER corpus also revealed no instances of the double forms. Similarly, we failed to find any in MilicÛÛ’s Century of Prose Corpus of over 500,000 words from the period 1680–1780 (see MilicÛÛ 1995), or in David Denison’s 19th century letter corpus of 100,000 words (see Denison 1994). Today the double forms are found primarily in the most colloquial registers of spoken English.
As far as linguistic conditioning factors for the two main variants are concerned, earlier scholars such as Pound (1901: 18) believed that the periphrastic and inflectional forms were in free variation and individual choice was the most important. She writes: “Throughout the [fifteenth] century when both methods are used, the form of comparison is governed by no fixed principle, such as length, ending, accent, or the source of the word. Instead the two methods are used quite indiscriminately, according to the author’s choice”. Similarly, with respect to the modern English period, Jespersen (1949: 347) said that although the choice was “subject to certain restrictions”, these were not fixed; thus, a “good deal is left to the taste of the individual speaker or writer”. In his view the “rules given in ordinary grammars are often too dogmatic”.
The diachronic investigation of the Helsinki Corpus revealed both text type and word structure as important factors. Generally speaking, inflectional forms prevail in matter-of-fact text types such as handbooks, and language written to reflect spoken or colloquial registers. Periphrastic forms are characteristic of more rhetorical texts such as philosophical and religious treatises, and correspondence. We will argue in 4 that this may be evidence for the origin of the periphrastic forms in written registers.
Modern grammarians generally recognize the length of the adjective and the nature of the word ending as the primary linguistic factors determining the choice between inflectional and periphrastic comparison. There is also an obvious connection between linguistic factors such as the length of the word, word origin (i.e. foreign v. native) and extralinguistic factors such as text type and register. Despite Pound’s assertion of free variation, word length emerged as a powerful factor in accounting for a good deal of the variation in the Helsinki Corpus material. In monosyllabic words the inflectional forms prevailed in some 70 percent of the instances with both comparative and superlative uses from the 1350s on and gained ground gradually, ending up with a 90 percent coverage of the data by the early 1700s. The material in the ARCHER corpus confirms this general trend, where the range of variation in the periods 1650 to 1900 is 90 to 95%. By contrast, in the Helsinki Corpus data words with four or more syllables always formed the comparative periphrastically; no more than four out of 51 instances formed the superlative inflectionally. Trisyllabic words allowed some variation, with 5 out of 100 examples forming comparatives inflectionally and 13 out of 152 examples forming the superlative inflectionally. In the ARCHER corpus words of three or more syllables always form comparatives periphrastically. The same is true of superlatives from 1700 onwards. Disyllabic words, however, present more fertile ground for variation both then and now.
In our sample from the British National Corpus word length and the nature of the word ending are also prime determinants of the variation between inflectional and periphrastic adjective forms. Table 5 shows that monosyllabic adjectives, which comprise the most frequent category accounting for 73% of the examples, form comparatives inflectionally in 99% of the total instances (N = 1,264). Among the exceptions are a handful of cases where the comparative is formed periphrastically, e.g. more nice, more rough, more cool, more rude, more cheap, more flat, more fresh, more right, more broad, more real, more dry, more wide, more hot.
It is possible there are some phonological as well as orthographic conditioning factors operative here, which we have not investigated. Jespersen (1949: 349), for instance, suggests that monosyllables ending in -d (e.g. mad), -t (e.g. fit) and -r (e.g. dear) take inflectional endings, even though he notes some exceptions such as dead, chaste, etc. Although orthographic considerations are not really relevant for our synchronic spoken material, they may be important for the earlier written corpora. Jespersen (1949: 346) indicates that some writers may prefer periphrasis with monosyllabic adjectives ending in -y (e.g. dry) to avoid orthographic complications. Inflectional comparative forms for these adjectives require decisions about whether to preserve the -y (e.g. dryer v. drier).
Table 5. Adjective length in syllables (British National Corpus). Infl. = inflectional forms, Peri. = periphrastic forms.
|
COMPARATIVE (N = 1,726) |
|||||||||||||||||||
| ONE | TWO | THREE | FOUR |
FIVE |
|||||||||||||||
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
|||||||||||||||
| SUPERLATIVE | |||||||||||||||||||
| ONE | TWO | THREE | FOUR | FIVE | |||||||||||||||
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
The figures include present and past participles found in adjectival uses. With disyllabic adjectives the use of the inflectional comparative drops to 65%. Adjectives containing three or more syllables invariably form their comparatives periphrastically. Likewise, for the superlatives, 98% of monosyllabic adjectives are of the inflectional type, while 64% of disyllabic adjectives are inflectional. Adjectives with three or more syllables are nearly always of the periphrastic type. There is, however, one exception in the trisyllabic category, i.e. frustratedest.
Again, the disyllabic adjectives are of the most interest for examining variation between inflectional and periphrastic comparison. Table 6 shows the distribution of competing forms in the British National Corpus according to the nature of the word ending. We have considered here only the clear and better represented categories. The data are, however, skewed in favor of adjectives ending in -y/-ly (e.g. happy, friendly, etc.), which account for 89% of the comparative forms and 86% of the superlatives.
Table 6. Word endings in disyllabic words (British National Corpus). Infl. = inflectional forms, Peri. = periphrastic forms.
|
COMPARATIVE (N = 261) |
|||||||||||||||
| -L/-LY | -LE/-ER | -FUL | -OUS | ||||||||||||
|
|
|
|
||||||||||||
|
|
|
|
||||||||||||
| SUPERLATIVE (N=101) | |||||||||||||||
| -L/-LY | -LE/-ER | -FUL | -OUS | ||||||||||||
|
|
|
|
||||||||||||
|
|
|
|
Moreover, the adjective easy covers a good deal of the data, slightly more than half (57% or 110 of the 194 cases) of the inflectional comparatives, and nearly a third (32% or 24 out of 76 cases) of the inflectional superlatives. In the category of inflectional comparatives another few adjective types provide most of the tokens, i.e. happy (N = 18), heavy (N = 13), early (N = 6), funny (N = 6), busy (N = 5), pretty (N = 4),10 and similarly for the inflectional superlatives, where funny (N = 7), heavy (N = 7), early (N = 6), ugly (N = 4) are the most frequent types.11 Likewise, for the periphrastic comparatives and superlatives, one adjective, likely, accounts for most of the tokens (N = 16, and N = 8, respectively).
The next most frequent group of disyllabic adjectives with a majority of inflectional comparatives and superlatives contains those ending in -le/-er, e.g. simple, proper, etc. The other adjectives ending in -ous (e.g. famous) or -ful (e.g. careful) always form comparatives and superlatives periphrastically. For adjectives ending in -ous, and other adjectives ending in sibilants, one might be tempted to suppose that the prime determinant of the preference for the periphrastic type of comparative with the superlative forms is phonological; namely, speakers will avoid the repetition of two sibilants, e.g. *foolishest, *famousest. Jespersen (1949: 355), however, found more superlatives than comparatives of the inflectional type.
Generally speaking, there are no big surprises here. Quirk et al. (1985: 462), for example, indicate that the disyllabic adjectives most readily able to take inflected forms are those ending in an unstressed vowel (e.g. easy, narrow), syllabic /l/ (e.g. simple), or schwa (with or without /r/) (e.g. clever). Although Quirk et al. (1985: 462) categorically rule out inflectional forms for trisyllabic adjectives, we did find one exception among the superlatives, i.e. frustratedest. Note, too, example (14) above, of a double superlative form with the inflectional ending, i.e. beautifulest. Otherwise, comparison is of the periphrastic type.
Table 7, which charts the incidence of the periphrastic forms for the three time periods, Late Middle English, Early Modern English and Modern English, allows us to pinpoint some key periods in the implementation and transition of the change. We have also included here data from 18th and 19th centuries from ARCHER to cover the time gap between the Helsinki Corpus and the British National Corpus. The graph in Figure 2 shows how the newer periphrastic type of adjective comparison has continued to gain ground for some groups of adjectives (i.e. those ending in -ful and -ous), while in others it lost some ground (i.e. those ending in -y/-ly and -le/-er) after initially gaining a foothold in the system earlier. Thus, we see a pattern of change familiar to variationists, where change proceeds stepwise by environments. It accelerates in some environments while in others it is inhibited.
Table 7. Percent of periphrastic forms of disyllabic adjective comparison in Late Middle, Early Modern and Contemporary English.
| COMPARATIVE | ||||
| -Y/-LY | -LE/-ER | -FUL | -OUS | |
| LME | 76 | 64 | 78 | 83 |
| EModE | 64 | 43 | 100 | 100 |
| 18th c | 60 | 54 | 100 | 100 |
| 19th c | 28 | 50 | 100 | 100 |
| PresE | 16 | 20 | 100 | 100 |
|
SUPERLATIVE |
||||
| LME | 64 | 63 | 92 | 92 |
| EModE | 48 | 75 | 95 | 100 |
| 18th c | 33 | 60 | 93 | 100 |
| 19th c | 27 | 33 | 100 | 100 |
| PresE | 13 | 25 | 100 | 100 |
Looking at the data for Late Middle English comparative forms, for example, we find that the new periphrastic type has not yet completely established itself in adjectives ending in -ous and -ful, where a small number of cases are still inflectional 1 (greuosere) out of 6 and 2 (joyfuller, two instances from the same text) out of 9, respectively.12 By the Early Modern English period, however, comparison is categorically periphrastic, as it is today. Thus, the Helsinki Corpus data capture one key transition from a formerly variable to a new invariant stage for this group of adjectives. Figure 2 shows a classic S-curve pattern of change for these adjectives with the final part of the log phase between the Late Middle and Early Modern English periods.
The periphrastic superlatives also greatly outnumber the inflectional superlatives from the Late Middle English period onwards. The data for superlative forms of adjective comparison show a similar trend for the group ending in -ous with 100% of these adjectives forming the superlative periphrastically by the Early Modern English period. The data from the ARCHER corpus allows us to show that superlatives for adjectives ending in -ful do not invariably take periphrastic forms until the 19th century.
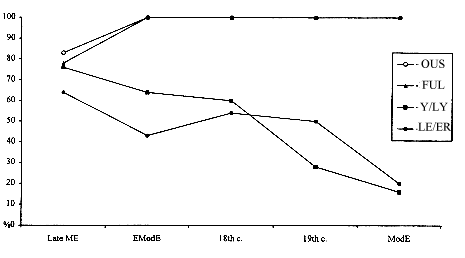
Figure 2. Percent of comparative periphrastic forms of disyllabic adjectives in Late Middle, Early Modern and Modern English.
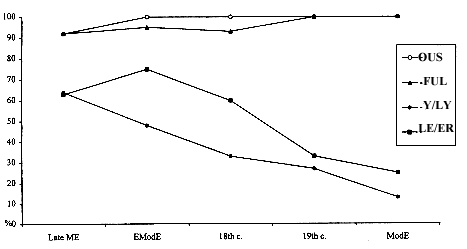
Figure 3. Percent of superlative periphrastic forms of disyllabic adjectives in Late Middle, Early Modern and Modern English.
While the periphrastic forms are consolidating themselves and replacing the inflectional forms in these groups of adjectives, they show a continuing decline for both superlative and comparative adjectives ending in -y/-ly and -le/-er. Thus, the use of the newer form appears to have peaked early during the Late Middle English period and the older inflectional type has been reasserting itself since the Early Modern period. The ARCHER corpus allows us to pinpoint the key transitions more precisely in time. For instance, for the comparative adjectives ending in -y/-ly a steep drop in the use of the periphrastic forms occurs between the 18th and 19th centuries, while for the adjectives ending in -le/-er, it occurs a century later.
Unfortunately, we cannot shed any direct light on developments in the spoken language during the earlier periods when the change began and the newer forms began to make inroads into the system. There are, however, at least three ways in which we can try to sharpen our understanding of the trajectory of change. One is by means of psycholinguistic experimentation to obtain acceptability judgements from speakers of present-day English and evidence for productivity of the two types of comparison (see Romaine 1983 for relevant methodology). This would be especially helpful for obtaining information about possible phonological and other conditioning factors for some of the infrequent adjective types.
A second one is by further investigation of register variation of the type begun with the Helsinki Corpus material. Here we will need to apply techniques of socio-historical reconstruction in order to obtain a fuller spectrum of text types and styles, particularly those most likely to reveal similarities to spoken language. We also need to examine, where possible, non-standard and regional varieties of English, which may have diverged from standard English with respect to this development (see Romaine 1982). Jespersen (1949: 356), for instance, observes the tendency towards more frequent use of inflection in what he calls ‘vulgar’ speech. Other scholars such as Knüpfer (1922) and Curme (1931) also mention similar variation. We hope to do further work on the topic in the future.
A third possibility is to extend the data base to include comparative data from other Germanic languages, in particular Swedish, where Nordberg (1985) has documented a recent increase in the use of periphrastic forms such as mera varm (‘more warm’) and den mest vackra (‘most pretty’) in modern Swedish at the expense of the older inflectional type, e.g. varmare (‘warmer’), den vackraste (‘prettiest’). The same tendency has also been noted for modern Danish, although as far as we know, no quantitative studies exist.
Nordberg’s data is especially interesting since it gives us a chance to witness the change in both spoken and written material over a thirty year period (1950–1980). By 1980 roughly 20% of forms were periphrastic and 80% inflectional. Notice that this compares quite closely with the situation in contemporary English, where inflectional forms prevail in 81% of cases overall (i.e. in comparatives and superlatives) and the inflectional forms in 19% of cases (see Table 3).13 While he found an increase in the newer periphrastic forms in both speech (from 15% to 24%) and writing (16% to 22%), Nordberg identifies spoken language as the spearhead of the change. Although the tendency towards periphrasis was first strongest in writing, it expanded more quickly in spoken language. This may well have happened in English too; although this will probably be impossible to show with empirical research due to lack of relevant material from the inception stage. Certainly Kytö’s finding that the periphrastic forms prevailed in the more rhetorical text types less likely to reflect spoken language is consistent with the possibility that the change in English might have begun in the written language and spread to the spoken. It is also possible that further work with older Swedish spoken material from before the 1950s will reveal more about the relationship between spoken and written registers and allow us to pinpoint more precisely the locus of the change.
Nordberg also took into account some of the same linguistic conditioning factors we did, such as morphological complexity of word structure, as well as additional ones, such as foreign v. native origin, part of speech, etc., which need further examination in English as we noted earlier. Not surprisingly, he found more periphrastic forms in more complex words, as well as in words of foreign origin; native and monosyllabic words favor the inflectional type and are most resistant to periphrasis, as they are in English.14
Overall, Nordberg discovered more comparatives of the periphrastic type than superlatives, though the difference is quite small (21% compared to 18%, respectively) in the Swedish data, unlike in our English data where superlatives more strongly favor periphrastic forms at all three time periods. Nevertheless, as we pointed out earlier, the relative difference between the frequencies of periphrastic comparatives and superlatives remains roughly the same over the three time periods with periphrastic superlatives around 9% to 10% more frequent than periphrastic comparatives. The actual frequencies, of course, show more variation because the periphrastic forms are in decline. In the late Middle English period 45% of comparative forms and 55% of superlatives are periphrastic, in the Early Modern English period 41% of comparatives and 50% of superlatives are periphrastic, while in modern English only 27% of superlatives and 16% of comparatives are periphrastic. In any case, closer examination of Nordberg’s data reveals some differences between spoken and written Swedish. More periphrastic comparatives occur in writing than in speech whereas in speech the reverse is true. There are more periphrastic superlatives than comparatives.
Nordberg also mentions, but dismisses, the possibility that English influence is responsible for the Swedish development on the grounds that there is no sign of a parallel change in German. He suggests instead the possibility of a splitting of the grammatical category of comparison along semantic lines, with the periphrastic and inflectional forms expressing different meanings, one being used to express comparison and the other to express degree or intensity without comparison. While this cannot be the only explanation, it merits further investigation in both English and Swedish.
As far as English is concerned, the possibility of meaning differences in the two types of comparison has not gone entirely unnoticed, though it has not been systematically investigated. Curme (1931: 504), for instance, credits the periphrastic form with a stylistic advantage. The use of a separate word (more/most) instead of an inflectional ending allows additional stress to be placed on the comparative element, if the speaker/writer wants to emphasize the idea of degree, or on the adjective to emphasize the meaning. Jespersen (1949: 356) too observes that the inflectional forms, particularly in the superlative and in longer words, are generally felt as “more vigorous” and “more emphatic” than the periphrastic forms, e.g. “the confoundedest, brazenest, ingeniousest piece of fraud” (Mark Twain). If we can demonstrate that there are systematic meaning differences in the two forms, we may well have found the explanation for the differences between spoken and written language and be able to confirm that the change began first in the written language. Spoken language always has the support of prosody to indicate which parts of the utterance the speaker wishes to emphasize. In the written language, however, such cues must be marked in other ways, e.g. through word order, punctuation, word choice, etc. It is possible that periphrasis emerged as a stylistic option first in the written language to emphasize and focus on the comparison itself rather than the quality referred to in the adjective.
Curme (1931: 500–1) also draws attention to the fact that adjective placement in relation to the noun may be a relevant factor; monosyllabic adjectives following nouns may take periphrastic form for emphasis. Compare: ‘There never was a kinder and juster man’ with ‘There never was a man more kind and just’. We have not looked here at the effects of the syntactic category to which the adjective belongs, i.e. attributive, predicate adjective, or present/past participle, nor at possible differences in their distribution in spoken and written registers.
Nordberg in fact found significant differences in the distribution of attributive and predicate adjectives in speech and writing. Although attributive adjectives were more common than predicate adjectives in writing, more periphrastic constructions with attributive adjectives occurred in speech than in writing.
We have presented an overview of variation in adjective comparison in modern spoken English using a sample of data from the British National Corpus. By comparing our synchronic data with the data from the Helsinki Corpus and the ARCHER corpus, we have been able to identify some of the key stages in the introduction, expansion and decline of the periphrastic forms. Inevitably some gaps remain, some of which we can fill in by further research with other corpora, both diachronic, such as ARCHER, as well as synchronic data bases. Recent projects concerned with compilation of bilingual corpora may provide some exciting possibilities for this kind of research. A case in point is the project ‘Text-based Contrastive Studies in English’ by Karin Aijmer, Bengt Altenberg and Mats Johansson, aiming at a corpus of Swedish and English machine-readable texts (see Aijmer et al. 1996).
We have concentrated for the moment on what is “more quicker, easier and more effective” to do with computer corpora, but a more comprehensive treatment of the topic of adjective comparison will have to pay close attention to the issue of meaning. This will require close scrutiny of individual texts and a more careful qualitative semantic analysis.
* We are grateful to Lou Burnard of Oxford University Computing Services for advice on the use of the British National Corpus and to Knut Hofland of Norwegian Computing Centre for the Humanities for help in handling the files. We are also indebted to Douglas Biber (Northern Arizona University) and Edward Finegan (University of Southern California) for access to the pilot version of the ARCHER corpus. Thanks also to Bengt Nordberg for helpful comments on the manuscript.
A variety of terms has been used to refer to the two types of comparison. Although the term ‘inflectional’ is not entirely accurate, since, strictly speaking, no inflection is involved (Pound 1901: 2), it is the one most commonly used. Because other terms such as ‘terminational’ (see e.g. Curme 1931) or ‘non-periphrastic’ have not been much used in recent literature, we will stick to the terms ‘inflectional’ and ‘periphrastic’ in this study (see Quirket al. 1985). We have also limited our study to gradable adjectives, excluding inflectional and periphrastic forms of adverb comparison.
The text types include: science, journals/diaries, letters, fiction, drama and sermons. The planned size of the ARCHER corpus is 1.7 million words.
Forms such as more quicker have been given various names such as double, multiple, pleonastic or hybrid. The majority of such forms are technically periphrastic in nature, with the exception of those comprised of certain defective adjectives such as worser, bestest, etc., which are inflectional.
The British National Corpus consists of a 90-million-word component of written texts and of a 10-million-word component of spoken texts. The texts included in the written component were sampled from the period 1960–1993, and those included in the spoken component collected during the project (1991–1994). The size and structure of the British National Corpus is described in Users Reference Guide for the British National Corpus (Version 1.0). For further information, see http://info.ox. ac.uk/ bnc/bncman.html.
Our searches were carried out on the basis of the words more and most, and the word class codes included in the British National Corpus (AJ0 = general or positive form, AJC = comparative adjective, AJS = superlative adjective). The British National Corpus was tagged automatically by using the CLAWS word class annotation scheme and, understandably enough, coding errors can be found in the 100-million-word corpus. In certain contexts the tagger has left relevant forms uncoded. When coming across with such instances, we have included them in the data. However, we have not made a systematic search of the examples possibly missing from our data.
We have not counted negative adjective comparisons with less/least since there is no corresponding inflectional form. There was a total of only 24 clear instances of less + adjective, e.g. less crowded. We did, however, find one example of a double form: ‘And make a bit less smaller to screw’.
I xal hem teche pleys fyn
and showe such myrthe as is in helle
It were more bettyr Amonges swyn
þat evyr more stynkyn þer be to dwelle
(M4/Mystery play/Ludus Coventriae 176; for full source references, see Kytö 1996b)
Wherfore, she is to me more better lady then ever she was before, insomuch that she hath promysed me hir good ladyship as long as ever she shall lyve; (E1/Private letter/Dorothy Plumpton 202)
J haue endeuoyred me to make an ende & fynysshe thys sayd translacion / and also haue enprynted it in the moost best wyse that I haue coude or myght (M4/Preface/ Caxton 70.C2)
8. We are indebted to Jonathan Culpeper for running the searches in the written component for us at the Lancaster University (the forms more better, most best, and bestest were included in the search, along with the other double forms recorded in our sub-corpus of spoken BNC data).
9. We use a dash to indicate a new speaker within an utterance and three points to indicate text omitted. For clarity, the codes found in the data base to indicate utterance attributes, word class tags, punctuation, etc. have been removed, but the following SGML codes have been kept (cf. Users Reference Guide 1995: 79): <trunc> = truncated form in a spoken text; <vocal> = non-verbal vocalization in a spoken text; <unclear> = incomprehensible or inaudible passage in a spoken text.
10. Moreover, in this group we have 3 adjectives with three occurrences (sporty, healthy, skinny), 3 with two (kinky, merry, handy), and 17 with only one (tasty, nasty, angry, dirty, noisy, likely, tidy, cocky, bulky, mucky, dressy, muddy, cosy, holy, fancy, shiny, wheezy).
11. In addition, this group includes 2 adjectives with three occurrences (nasty, busy), 4 with two (happy, dirty, pervy, pretty), and 14 with only one (crazy, chewy, healthy, pushy, noisy, foggy, lucky, cocky, greeny, grassy, tiny, tasty, horny, raunchy).
12. Anoþer es ‘Avowtry,’ and þat es spousebreke, wheþer it be bodyly or it be gastely, þat greuosere and gretter es þan þe toþer. (M3/4/Sermon/Gaytryge 14)
. ye fede vs so bounteuesly with behest shewyng of your good lordship to vs in tyme comyng, as ye haue euer don, that now and euer we shulle be the joyfuller in this lyfe whan we remembre vs on so noble a grace. (M3/Official letter/A Book of London English 75)
. plese it your benigne grace to conceye that in pesibler degre, treta[b]ler gouernaunce, ne Joyfuller rest, as ferforth as absence of you þat as our most soueraign and excellent lord may suffre, was neuer erthly Cite ne toun, y-blessed be God. (Idem, p. 73)
13. Nordberg excluded double comparatives such as mer svårare ‘more harder’ from his study, but does not give an indication of how frequent they are. Nordberg (personal communication), however, confirms that such forms do occur in spoken Swedish, even if only infrequently, and that they may even be increasing. Moreover, according to Nordberg many of the forms must be considered as slips of the tongue and would probably be corrected in either way if the speakers were made aware of them.
14. Nordberg’s results are not entirely comparable here to ours because his criterion of morphological/word structure is not based straightforwardly on number of syllables as is ours. His category of morphologically simple contains some derived adjectives which are di- and trisyllabic, e.g. aktsam ‘careful’, odräglig ‘intolerable’, an in-between category “Oviss” (‘uncertain’), adjectives with the prefixo-, etc. There is a great deal of internal variation in this category. A further source for differences between Nordberg’s and our data is that Nordberg has excluded some categories which display categorical use of one of the forms (Nordberg 1985: 93–4).
Aijmer, Karin, Bengt Altenberg & Mats Johansson (1996). “Text-based Contrastive Studies in English. Presentation of a Project”. Languages in Contrast. Papers from a Symposium on Text-based Cross-linguistic Studies, Lund 4–5 March 1994 (Lund Studies in English, 88), ed. by Karin Aijmer, Bengt Altenberg & Mats Johansson, 73– 85. Lund: Lund University Press.
Biber, Douglas, Edward Finegan & Dwight Atkinson (1994a). “ARCHER and Its Challenges: Compiling and Exploring a Representative Corpus of Historical English Registers”. Creating and Using English Language Corpora. Papers from the Fourteenth International Conference on English Language Research on Computerized Corpora, Zürich 1993, ed. by Udo Fries, Gunnel Tottie & Peter Schneider, 1–13. Amsterdam & Atlanta, GA: Rodopi.
Biber, Douglas, Edward Finegan, Dwight Atkinson, Ann Beck, Dennis Burges & Jena Burges (1994b). “The Design and Analysis of the ARCHER Corpus: A Progress Report [A Representative Corpus of Historical English Registers]”.Corpora Across the Centuries. Proceedings of the First International Colloquium on English Diachronic Corpora, St Catharine’s College Cambridge, 25–27 March 1993, ed. by Merja Kytö, Matti Rissanen & Susan Wright, 3–6. Amsterdam & Atlanta, GA: Rodopi.
BNC = The British National Corpus (May 1995). Oxford: Oxford University Computing Services.
Curme, George O. (1931). A Grammar of the English Language. Volume II: Syntax. D. C. Heath & Company [Reprint 1977. Essex, CT: Verbatim Printing.].
Denison, David (1994). “A Corpus of Late Modern English Prose”. Corpora Across the Centuries. Proceedings of the First International Colloquium on English Diachronic Corpora, St Catharine’s College Cambridge, 25–27 March 1993, ed. by Merja Kytö, Matti Rissanen & Susan Wright, 7–16. Amsterdam & Atlanta, GA: Rodopi.
Helsinki Corpus = The Helsinki Corpus of English Texts (1991). Helsinki: Department of English, University of Helsinki.
Jespersen, Otto (1949). A Modern English Grammar on Historical Principles. Part VII: Syntax. Copenhagen: Ejnar Munksgaard & London: George Allen & Unwin.
Knüpfer, Hans (1922). Die Anfange der periphrastischen Komparation im Englischen. Diss. Heidelberg. Also in: Englische Studien 55 (1921), 321–389.
Kytö, Merja (1996a). “‘The Best and Most Excellentest Way’: The Rivalling Forms of Adjective Comparison in Late Middle and Early Modern English”. Words. Proceedings of an International Symposium, Lund, 25–26 August 1995 (Konferenser, 36), ed. by Jan Svartvik, 123–144. Stockholm: Kungl. Vitterhets Historie och Antikvitets Akademien.
_____, comp. (1996b). Manual to the Diachronic Part of the Helsinki Corpus of English Texts. Coding Conventions and Lists of Source Texts. (3rd ed.). Helsinki: Department of English, University of Helsinki.
MilicÛÛ, Louis T. (1995). “The Century of Prose Corpus: A Half-Million Word Historical Data Base”. Computers and the Humanities 29, 327–337.
Mitchell, Bruce (1985). Old English Syntax. I. Oxford: Clarendon Press.
Nordberg, Bengt (1985). “Vad händer med adjektivets ändelsekomparation?” Det mångskiftande språket. Om variation i nusvenskan (Ord och stil. Språkvårdssamfundets skrifter, 14), ed. by Bengt Nordberg, 88–103. Lund: Liber Förlag.
Pound, Louise (1901). The Comparison of Adjectives in English in the XV and the XVI Century (Anglistische Forschungen, 7.) Heidelberg: Carl Winter.
Quirk, Randolph, Sidney Greenbaum, Geoffrey Leech & Jan Svartvik (1985). A Comprehensive Grammar of the English Language. London & New York: Longman.
Rohr, Anny (1929). Die Steigerung des neuenglischen Eigenschaftswortes im 17. und 18. Jahrhundert mit Ausblicken auf den Sprachgebrauch der Gegenwart. Diss. Giessen.
Romaine, Suzanne (1982). Socio-historical Linguistics. Its Status and Methodology. Cambridge: Cambridge University Press.
_____ (1983). “On the Productivity of Word Formation Rules and the Limits of Variability in the Lexicon”. Australian Journal of Linguistics 3, 176–200.
Users Reference Guide for the British National Corpus. Version 1.0. (May 1995). Oxford University Computing Services.